EdgeSounds’ RatHole (former GenieSys RatHole) is a free unique nondestructive universal compression utility. Its function is based on a principle of self-training neural networks. EdgeSounds RatHole was especially designed for nondestructive compression of any files containing audio data in PCM 8/16/24 bit or IEEE_FLOAT 32 bit format.
A new EdgeSounds compression algorithm makes it possible to efficiently reduce the size of packed audio data and later unpack exactly same bits, with no difference to the original data. The compression algorithm compresses audio data, considering the bit depth of the digital data contained in the audio file (8/16/24/32 bit). The algorithm is proven to be equally effective on compressing the following file types:
- Audio files WAV, AU, AIFF, SND;
- Ensoniq Paris PAS;
- Sample sound banks such as:
- AVM Apex bank file APEX
- Aureal sound bank ARL
- Creative Labs/E-mu System SoundFont banks format 1&2.x SBK, SF2;
- Downloadable sounds level 1&2 DLS;
- Ensoniq EPS Files EFE, Ensoniq Instruments family files INS, Ensoniq Disk Image GKH;
- Gravis Ultrasound /Forte Patch PAT;
- Kurzweil 2000-2600 files KRZ;
- Nemesys/Tascam GIG;
- Seer Systems Reality banks SEERBANKSET;
- Turtle Beach WaveFront Bank WFB;
- Virtual Sampler bank VSB;
- Multi-track audio data as Cakewalk/Sonar BUN, CWB;
- Impulse Tracker instrument ITI, Fast Tracker 2 instrument XI;
- any other formats containing audio data
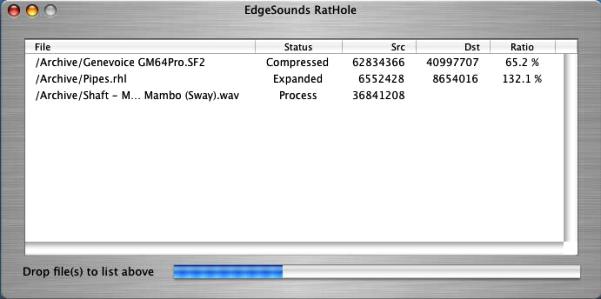
The compression ratio of the algorithm depends on the size of audio data, the balance between the tone and noise component, bit depth and other factors, and usually varies from 36% to 78% or even more, with an average of 48-56%. The higher is the bit depth and the fidelity of audio data, the better is the compression ratio.
The RatHole can be successfully used as a common archiving utility for any other file types as well.
www.edgesounds.com/Products/Software/RatHole
www.rarewares.org/others.php#edgesounds-rathole